How to scrape stock upgrades and downgrades from Yahoo Finance
- Dec 2, 2019
In this blog post I’ll show you how to scrape stock upgrade and downgrade data from Yahoo Finance using Python, Beautiful Soup, json, and a bit of regular expression magic.
This technique can be applied to any stock symbol on Yahoo Finance, but for this blog post we’ll be scraping data for Apple (AAPL).
I’ll be guiding you through the process, describing my thought processes and techiques, and if you follow along, by the end of this blog post, you’ll have extracted stock upgrade and downgrade data in a Pandas dataframe which will look something like this:
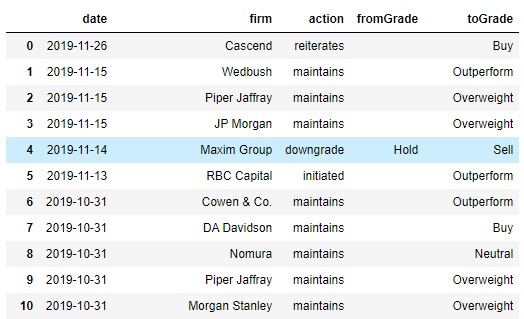
From there, you can easily export the data into an Excel file, or if you’re a more advanced Python user, host the code in a Web API which can be accessed by Google Sheets, or your own custom code.
Disclaimers
Before we start, a few disclaimers:
- This code doesn’t come with any guarantee or warranty.
- I’m not a financial advisor. This blog post doesn’t represent financial advice.
- I don’t recommend the use of this code for any investment decisions.
- This code is designed for personal use, and isn’t designed for high-volume extractions.
Prerequisites
Make sure you have installed the Anaconda distribution of Python .. this includes Jupyter Notebook, which we’ll use throughout this blog post.
Now we begin!
Find the ticker symbol
For this example, we’ll be scraping data for Apple.
In Yahoo Finance, the symbol for Apple is AAPL
Take a look at the data that we’re going to scrape
Here’s an example of the AAPL upgrades and downgrades table that we’re going to extract. There may be new data since this article was created, so your table may look a little different.
You can click on the “More Upgrades & Downgrades” button to see the full list. We’ll be scraping the full list.

Inspect this table in the Chrome debugger, and you’ll see that the table matches what’s displayed, something like this:

You’ll see that the full list of upgrades and downgrades isn’t contained in the table, so we’re going to need to look for the data somewhere else.
Now take a look at the page source and search for “RBC Capital” or one of the other listed firms to see if the data is contained somewhere else in the page.

There it is, contained within a large json blob, now scroll up until you see the beginning of the json blob:

Above, you can see:
- The json blob is in a
<script>tag - The json blob is wrapped in a
(function (root) { - The json blob that contains our data is within the function, set to
root.app.main
There are a couple of ways that we could extract this, but the easiest might be with Beautiful Soup and a regular expression to fetch the json blob, then using a json parser to read the json data.
Start scraping
Open up a new Jupyter notebook, and read the page in via Beautiful Soup:
import re
import json
from bs4 import BeautifulSoup
url = 'https://finance.yahoo.com/quote/AAPL/analysis?p=AAPL'
page = requests.get(url)
soup = BeautifulSoup(page.content, "lxml")Now extract the script block which contains the json blob:
script = soup.find('script', text=re.compile('root\.App\.main'))
scriptThe code above is using find(…) to search the document for a script tag, then using re.compile to filter for the script tag which contains root.App.main, the variable which the json blob is assigned to.
Now, we can use a regular expression to extract the json blob.
To build up the regular expression, I copied the entire script block into Regexr to help build up the regular expression. Make sure you’ve enabled multiline in the Flags dropdown so that you can capture the entire json blob:

Regexr has a nice explainer tool, and cheat sheet on the sidebar, which makes it way easier to build regular expressions.
Then use the regular expression to extract the json blob:
json_text = re.search(r'^\s*root\.App\.main\s*=\s*({.*?})\s*;\s*$',
script.string, flags=re.MULTILINE).group(1)
data = json.loads(json_text)
dataThe key above is the capturing group, which will contain the json blob, and looks like: ({.*?}), and the call to group(1), which returns the data from within the capturing group, so that json_text is the extracted json blob.
Once the json blob has been extracted, we can then call json.loads to decode the json blob into a Python object.
Then copy+paste the json data into a json viewer such as jsoneditoronline.org, and search for the upgradeDowngradeHistory json key, which contains the upgrade and downgrade data:

You can see in the screenshot above, that it’s in the node:
context->dispatcher->stores->QuoteSummaryStore->upgradeDowngradeHistory->history
so let’s fetch it, and put it into a Pandas dataframe:
upgrades_and_downgrades = data['context']['dispatcher']['stores']['QuoteSummaryStore']['upgradeDowngradeHistory']['history']
df = pd.DataFrame(upgrades_and_downgrades)Run the cell, and you’ll see something like this:

The epochGradeDate represents the date that the Upgrade/Downgrade was added, but it’s not very useful in it’s epoch form. Let’s convert it to a familar date format:
df['date'] = pd.to_datetime(df['epochGradeDate'], unit='s')
df = df.drop(columns=['epochGradeDate'])Run the cell, and you’ll see something like this:

Better!
The data in the action column is not very readable either; it took me a bit to work out that ‘reit’ means ‘reiterates’ and ‘main’ means ‘maintains’… let’s convert the action column to an easier to read format:
action_map = {
'init': 'initiated',
'down': 'downgrade',
'reit': 'reiterates',
'up': 'upgrade',
'main': 'maintains'
}
df['action'] = df['action'].apply(lambda x: action_map[x])Run the cell, and you should see something like:

Finally, reorder the columns however you like, such as:
df[['date', 'firm', 'action', 'fromGrade', 'toGrade']]
dfRun the cell, and you should see something like:

You can then export the data frame to an Excel file via:
df.to_excel('aapl-upgrades-downgrades.xlsx')The Excel file will be saved to the same path as your Jupyter notebook file.
The complete set of code
It took a bit of work to get here, but the final set of code is fairly concise:
import re
import json
from bs4 import BeautifulSoup
url = 'https://finance.yahoo.com/quote/AAPL/analysis?p=AAPL'
page = requests.get(url)
soup = BeautifulSoup(page.content, "lxml")
script = soup.find('script', text=re.compile('root\.App\.main'))
json_text = re.search(r'^\s*root\.App\.main\s*=\s*({.*?})\s*;\s*$',
script.string, flags=re.DOTALL | re.MULTILINE).group(1)
data = json.loads(json_text)
upgrades_and_downgrades = data['context']['dispatcher']['stores']['QuoteSummaryStore']['upgradeDowngradeHistory']['history']
df = pd.DataFrame(upgrades_and_downgrades)
df['date'] = pd.to_datetime(df['epochGradeDate'], unit='s')
df = df.drop(columns=['epochGradeDate'])
action_map = {
'init': 'initiated',
'down': 'downgrade',
'reit': 'reiterates',
'up': 'upgrade',
'main': 'maintains'
}
df['action'] = df['action'].apply(lambda x: action_map[x])
df[['date', 'firm', 'action', 'fromGrade', 'toGrade']]What’s next?
From there, there’s lots of options such as:
- Export the data to Excel
- Export the data to Google Sheets
- Host the scraper as a web service
Send me an email or leave a comment below and let me know your use case.
Thanks for reading! Enjoyed this article? Follow me on Twitter.
